
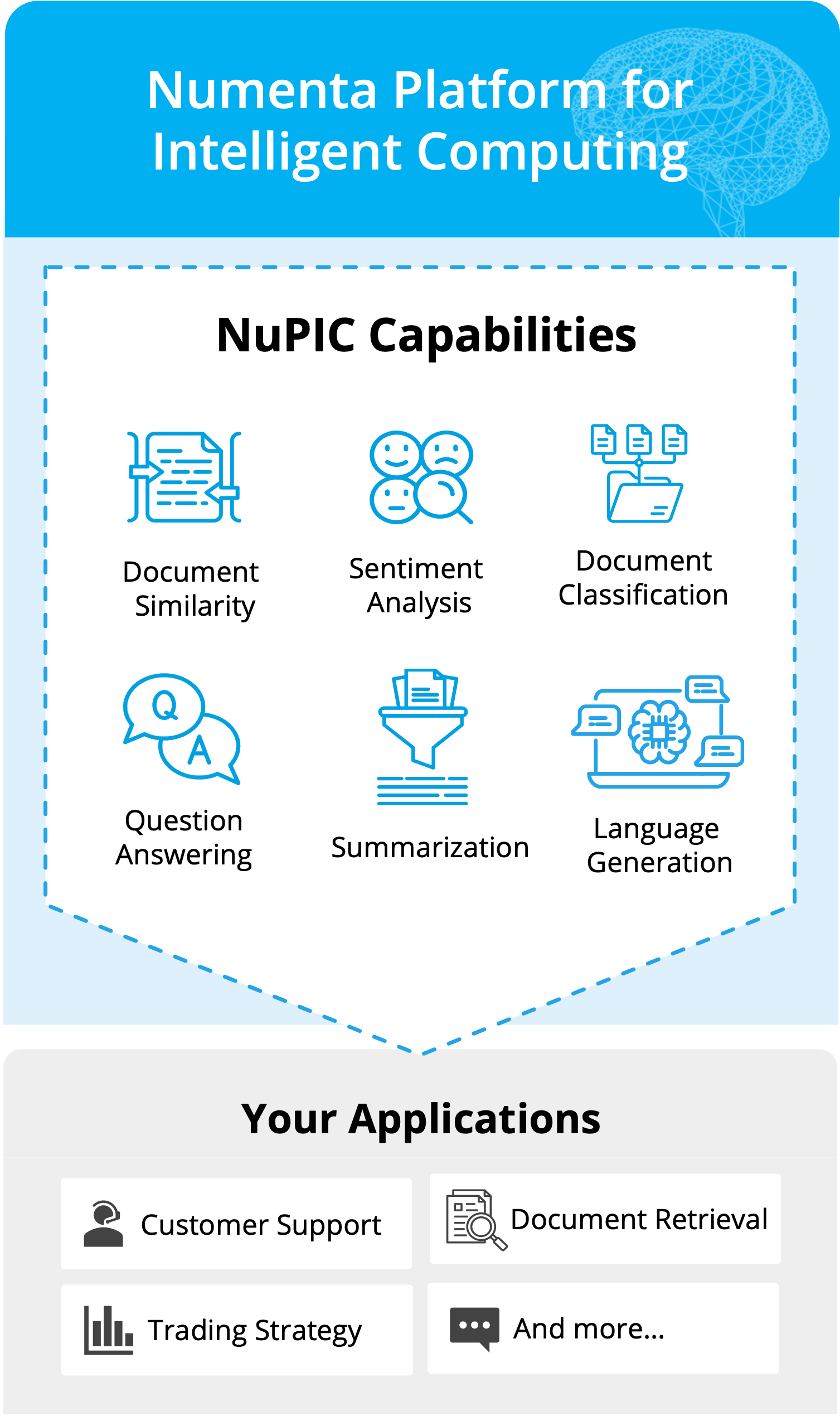
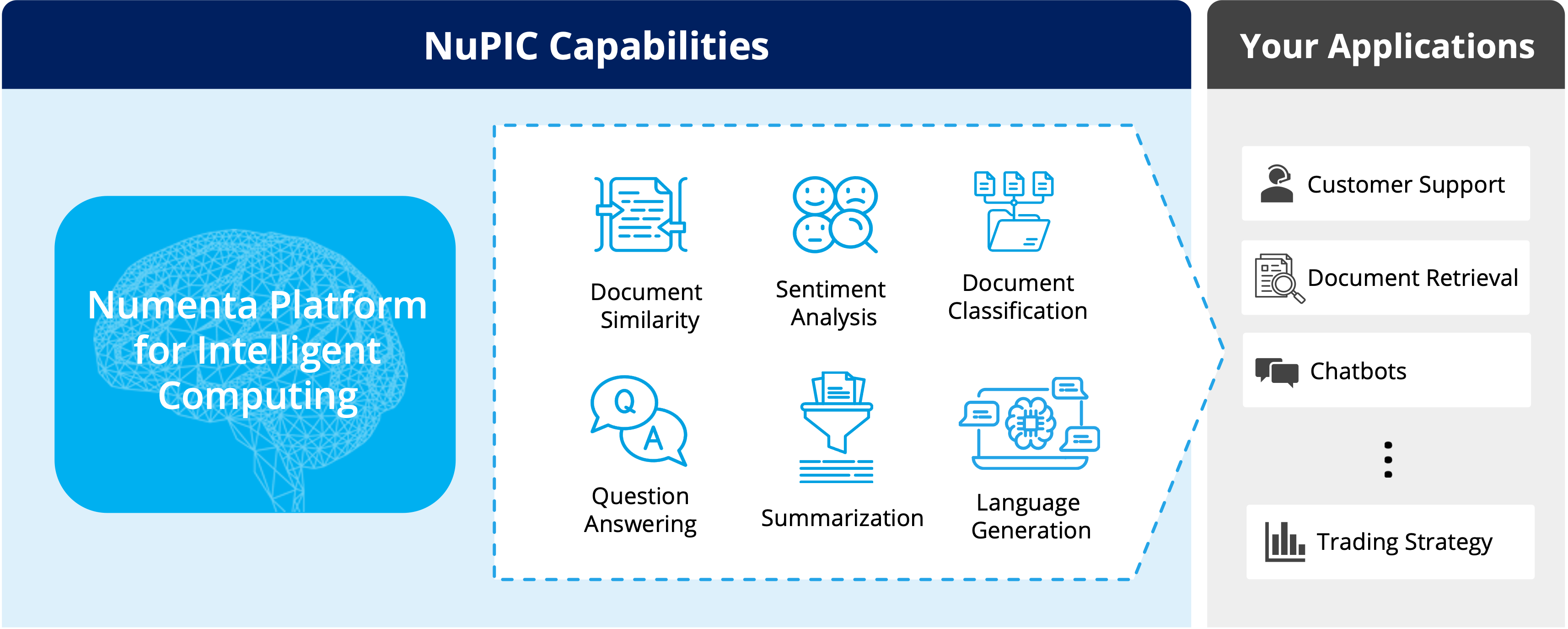

Optimal performance
Ideal for real-time applications

Multi-tenancy
Run hundreds of models on the same server

Effortless scaling
Easily scale CPU-only systems

Simplified MLOps
Easy infrastructure management
"Our latest game, Proxi, is an expansive interactive world populated by your personal memories and connections. We turned to Numenta because of fundamental challenges we faced in incorporating AI – not only to deliver the best experience possible to our players, but also ensure that we never jeopardize the trust and privacy they place in us. With NuPIC, we can run LLMs with incredible performance on CPUs and use both generative and non-generative models as needed. And, because everything is on-prem, we have full control of models and data.
Over time, Numenta’s cutting edge neuroscience driven research will enable us to build simulated AI players that continuously learn, adapt and behave in truly intelligent fashion. We are excited by the possibilities!"
"We were able to deploy NuPIC easily and see immediate performance improvements of LLMs on CPUs. This is the type of solution our larger and more advanced 100E Singapore customers are asking for. They want to be able to fine-tune both generative and non-generative LLMs and keep their data private within their premise when possible. The Numenta solution helps accelerate our mission to strengthen Singapore’s AI capabilities across our diverse group of 100E customers."

"The team at Gallium were looking for ways to meet the high-throughput, low-latency demands of real-time natural language processing applications. They turned to Intel and our partner Numenta to help with this challenge...for pretty amazing results, and pretty amazing savings."


Boosting accuracy without compromising performance: Getting the most out of your LLMs
With our neuroscience-based optimization techniques, we shift the model accuracy scaling laws such that at a fixed cost, or a given performance level, our models achieve higher accuracies than their standard counterparts.

20x inference acceleration for long sequence length tasks on Intel Xeon Max Series CPUs
Numenta technologies running on the Intel 4th Gen Xeon Max Series CPU enables unparalleled performance speedups for longer sequence length tasks.

Numenta + Intel achieve 123x inference performance improvement for BERT Transformers
Numenta technologies combined with the new Advanced Matrix Extensions (Intel AMX) in the 4th Gen Intel Xeon Scalable processors yield breakthrough results.